6.2. Overlap IO
IPU 在执行推理模型时, 一般分成 3 个阶段:
Load: 从 Host 拷贝输入数据到 IPU
Compute: 模型计算
Store: 从 IPU 拷贝结果数据到 Host
这三个阶段是串行执行的, 也就是说在 Load/Store 阶段传输数据时, IPU 的计算资源是闲置状态. 这在一些输入输出数据比较大的模型中, 整个模型的性能是受 IO 限制的. 对于这种模型, 开启 Overlap IO 能够使计算阶段和 IO 阶段重叠起来, 提高 IPU 的计算资源利用率.
6.2.1. 原理
Overlap IO 的原理是通过把 IPU 的片上所有 Tile 划分成两组, 即 Compute Tiles 和 IO Tiles, Compute Tiles 专门处理计算, 而 IO Tiles 专门负责与 Host 之间进行数据拷贝. 这样, 对于一个计算流来说, Load, Compute, Store 三个阶段组成了一个三级的 pipeline, 从而使计算和 IO 重叠起来, 提高 IPU 计算资源的利用率.
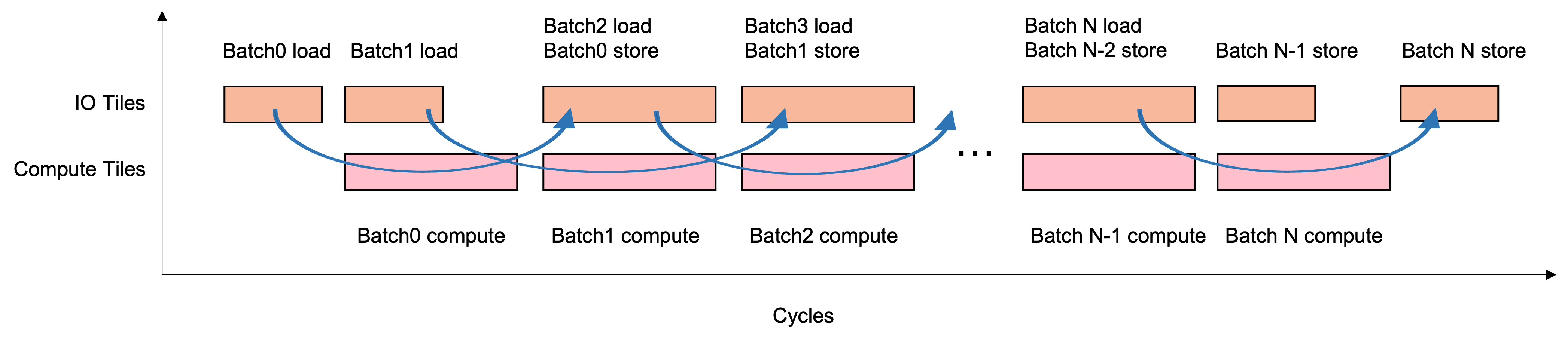
Fig. 6.1 Load/Compute/Store 组成的 pipeline
6.2.2. 配置 IO Tiles
Overlap IO 的开启只需要设置一个参数, 即 IO Tiles 的数量. 可以调整 IO Tiles 的数量来优化传输的吞吐量. 要计算 IO Tiles 的数量, 可以用所有输入输出的 Tensor 大小之和除以每个 Tile 可用的 SRAM 大小, 然后四舍五入到下一个 2 的幂次方.
通过 PopRT CLI 中
--num_io_tiles来配置 IO Tiles:
poprt \
--input_model model.onnx \
--export_popef \
--output_dir model \
--num_io_tiles 128
通过
poprt.compiler.CompilerOptionsAPI 来配置 IO Tiles:
opts = poprt.compiler.CompilerOptions()
opts.num_io_tiles = 128
6.2.3. 调试
通过 PopVision Graph Analyser 工具, 可以观察 IO 和 Compute 是否重叠, 从而来判断 OverlapIO 是否生效, 以及通过调整 IO Tiles 的数量来优化模型的性能.

Fig. 6.2 Overlap IO 使得 IO 和 Compute 互相掩盖
6.2.4. 并发请求
由于通过 Overlap IO 把推理的 3 个阶段组成了一个三段式的流水线, 因此, 为了能维持流水线运行下去, 必须要有足够的并发数据喂给 IPU. 通过多线程的方式给 IPU 并发的喂数据, 至少需要启动 3 个线程.
6.2.5. 示例
下面是一个简单的 OverlapIO 的 example code:
1# Copyright (c) 2022 Graphcore Ltd. All rights reserved.
2import argparse
3import threading
4
5import numpy as np
6import onnx
7
8from onnx import helper
9
10from poprt import runtime
11from poprt.compiler import Compiler, CompilerOptions
12from poprt.runtime import RuntimeConfig
13
14'''
15PopRT use OverlapInnerLoop strategy as default exchange strategy.
16There are two loops in the main program: outer loop and inner loop.
17Each batch data needs to be processed in three pipeline stages: load/compute/store.
18Therefore, in order to enable the pipeline to run normally, at least three threads
19are required to feed data to the pipeline at the same time.
20==============================================================
21OverlapInnerLoop:
22- Boxes denote subgraphs / subgraph Ops / loops
23- Inputs/outputs are loop carried in order
24
25.- outer loop ----------------------------------------.
26| .- inner loop -. |
27| load - compute - | - store | |
28| load - | - compute -- | - store |
29| | load ----- | - compute - store |
30| '--------------' |
31'-----------------------------------------------------'
32 ^^^^^^^ ^^^^^^^ ^^^^^^^
33 overlap overlap overlap
34
35==============================================================
36'''
37
38
39def compile(model: onnx.ModelProto, args):
40 """Compile ONNX to PopEF."""
41 model_bytes = model.SerializeToString()
42 outputs = [o.name for o in model.graph.output]
43
44 options = CompilerOptions()
45 options.batches_per_step = args.batches_per_step
46 options.num_io_tiles = args.num_io_tiles
47
48 executable = Compiler.compile(model_bytes, outputs, options)
49 return executable
50
51
52def run(executable, args):
53 """Run PopEF."""
54 # Create model runner
55 config = RuntimeConfig()
56 config.timeout_ns = 0
57 # Create model runner
58 model_runner = runtime.ModelRunner(executable, config)
59
60 inputs_info = model_runner.get_model_inputs()
61 outputs_info = model_runner.get_model_outputs()
62
63 # Run in multiple threads
64 def execute(bps, inputs_info, outputs_info):
65 inputs = {}
66 outputs = {}
67
68 for input in inputs_info:
69 inputs[input.name] = np.random.uniform(0, 1, input.shape).astype(
70 input.numpy_data_type()
71 )
72 for output in outputs_info:
73 outputs[output.name] = np.zeros(
74 output.shape, dtype=output.numpy_data_type()
75 )
76
77 # To correctly generate the popvision report, iteration must be a
78 # multiple of batches_per_step and greater than 2 * batches_per_step
79 # There are 3 threads, so the total number feed into IPU is 3 * iteration
80 iteration = bps
81 for _ in range(iteration):
82 model_runner.execute(inputs, outputs)
83
84 threads = []
85 num_threads = 3
86 print(f"Run PopEF with {num_threads} threads.")
87 for _ in range(num_threads):
88 threads.append(
89 threading.Thread(
90 target=execute, args=(args.batches_per_step, inputs_info, outputs_info)
91 )
92 )
93
94 for t in threads:
95 t.start()
96
97 for t in threads:
98 t.join()
99 print(f"Complete.")
100
101
102def default_model():
103 TensorProto = onnx.TensorProto
104
105 nodes = []
106 num_matmuls = 4
107 nodes.append(helper.make_node("Expand", ["input", "shape"], ["Act0"]))
108 for i in range(num_matmuls):
109 nodes.append(helper.make_node("MatMul", [f"Act{i}", "Weight"], [f"Act{i+1}"]))
110 nodes.append(
111 helper.make_node("ReduceMean", [f"Act{num_matmuls}"], ["output"], axes=[0, 1])
112 )
113
114 graph = helper.make_graph(
115 nodes,
116 "matmul_test",
117 [
118 helper.make_tensor_value_info("input", TensorProto.FLOAT, (256, 256)),
119 ],
120 [helper.make_tensor_value_info("output", TensorProto.FLOAT, (256, 256))],
121 [
122 helper.make_tensor(
123 "shape",
124 TensorProto.INT64,
125 [4],
126 np.array([4, 4, 256, 256], dtype=np.int64),
127 ),
128 helper.make_tensor(
129 "Weight",
130 TensorProto.FLOAT,
131 (4, 4, 256, 256),
132 np.random.randn(4, 4, 256, 256),
133 ),
134 ],
135 )
136 opset_imports = [helper.make_opsetid("", 11)]
137 original_model = helper.make_model(graph, opset_imports=opset_imports)
138 return original_model
139
140
141if __name__ == '__main__':
142 parser = argparse.ArgumentParser(
143 description='Convert onnx model and run it on IPU.'
144 )
145 parser.add_argument(
146 '--batches_per_step',
147 type=int,
148 default=16,
149 help="The number of on-chip loop count.",
150 )
151 parser.add_argument(
152 '--num_io_tiles',
153 type=int,
154 default=192,
155 help="The number of IO tiles.",
156 )
157 args = parser.parse_args()
158 model = default_model()
159 exec = compile(model, args)
160 run(exec, args)