6.6. Model Fusion
对于 Poplar 来说, 模型会先编译成在 IPU 上可执行的二进制 executable, 然后加载到 IPU 中执行. 由于 Poplar 目前只支持同一时刻加载一个 executable, 如果在一颗 IPU 上执行多个模型, 会造成反复加载不同的 executable, 从而导致性能急剧下降.
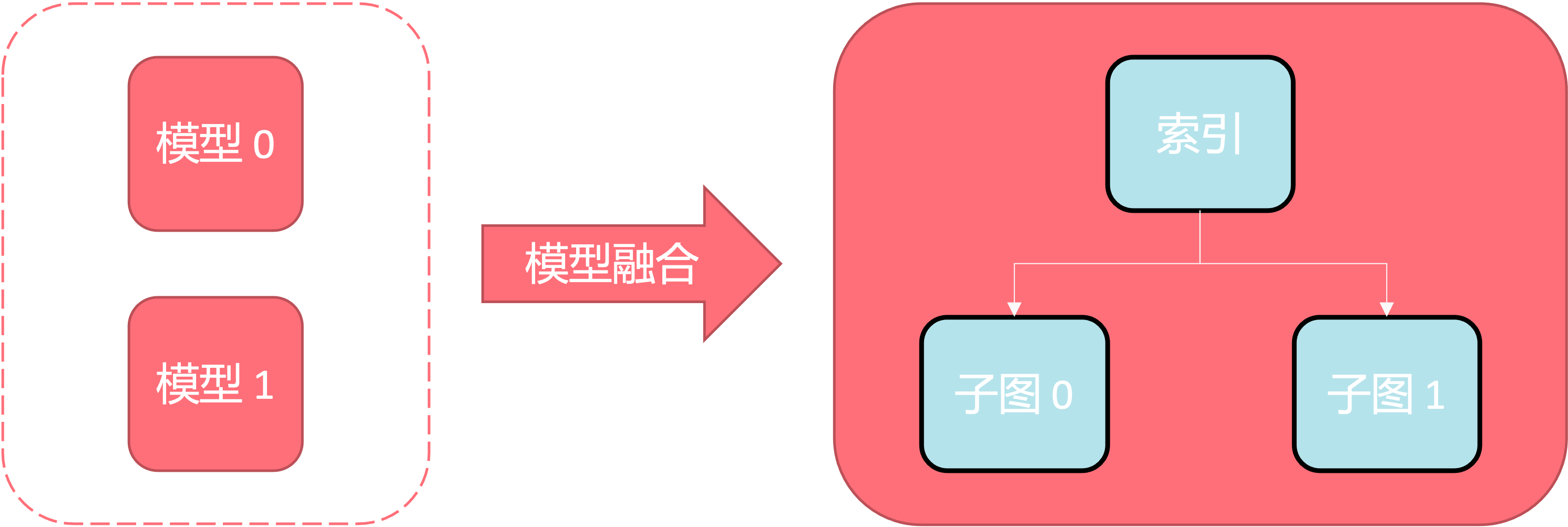
模型融合功能, 是在编译阶段, 将多个用户模型融合成一个模型, 每个模型作为融合后模型的一个子图, 子图和子图之间通过分支算子隔离. 在运行时, 通过输入模型索引来控制运行哪个子图, 可以大幅减少模型切换的延时.
本教程将展示如何在 PopRT 中实现模型融合并运行. 在阅读本教程之前, 假设读者已经了解以下主题:
6.6.1. 实现 PopRT 模型融合
目前该特性只支持通过 yaml 配置文件的方式来启动, 用户需要提供 yaml 格式的配置文件, 文件内定义有需要融合的 onnx 模型以及相关参数.
yaml 文件示例如下:
1output_dir: './'
2output_model: 'executable'
3export_popef: True
4max_tensor_size: -1
5ipu_version: 'ipu21'
6model_fusion:
7 - input_model: 'model0.onnx'
8 input_shape: ['X=1,2', 'Y=1,2']
9 precision: 'fp32'
10
11 - input_model: 'model1.onnx'
12 input_shape: ['X=1,1']
13 precision: 'fp16'
可以在 model_fusion 中为各模型配置独立的参数, 但请注意目前模型融合只支持两个模型. model_fusion 之外的参数是全局参数,它们会对每个待融合模型生效.
例如, 示例中的 max_tensor_size = -1, 因为它定义在全局参数中, 所以会作用于所有模型.
融合后的模型需要通过 PopRT Runtime 来运行, 因此, 必须设置 export_popef 为 True 以生成 PopEF.
此外, 为了保证后续推理代码的运行, 需要根据运行的设备, 正确设置 ipu_version, 如 C600 平台, 需要设置 ipu21.
模型融合代码示例如下:
1# Copyright (c) 2023 Graphcore Ltd. All rights reserved.
2import os
3
4import numpy as np
5import onnx
6
7from onnx import TensorProto, checker, helper, mapping
8
9
10def create_model0(opset_version=11):
11 g0_dtype = TensorProto.FLOAT
12 g0_add = helper.make_node("Add", ["X", "Y"], ["Z"])
13 g0_reshape = helper.make_node("Reshape", ["Z", "C"], ["O"])
14 g0 = helper.make_graph(
15 [g0_add, g0_reshape],
16 'graph',
17 [
18 helper.make_tensor_value_info("X", g0_dtype, (1, 2)),
19 helper.make_tensor_value_info("Y", g0_dtype, (1, 2)),
20 ],
21 [
22 helper.make_tensor_value_info("O", g0_dtype, (2,)),
23 ],
24 )
25
26 g0_const_type = TensorProto.INT64
27 g0_const = helper.make_tensor(
28 "C",
29 g0_const_type,
30 (1,),
31 vals=np.array([2], dtype=mapping.TENSOR_TYPE_TO_NP_TYPE[g0_const_type])
32 .flatten()
33 .tobytes(),
34 raw=True,
35 )
36 g0.initializer.append(g0_const)
37 m0 = helper.make_model(g0, opset_imports=[helper.make_opsetid("", opset_version)])
38 checker.check_model(m0)
39 return m0
40
41
42def create_model1(opset_version=11):
43 g1_dtype = TensorProto.FLOAT16
44 g1_concat = helper.make_node("Concat", ["X", "C"], ["O"], axis=1)
45 g1 = helper.make_graph(
46 [g1_concat],
47 'graph',
48 [
49 helper.make_tensor_value_info("X", g1_dtype, (1, 1)),
50 ],
51 [
52 helper.make_tensor_value_info("O", g1_dtype, (1, 3)),
53 ],
54 )
55
56 g1_const = helper.make_tensor(
57 "C",
58 g1_dtype,
59 (1, 2),
60 vals=np.array([[1.5, 2.0]], dtype=mapping.TENSOR_TYPE_TO_NP_TYPE[g1_dtype])
61 .flatten()
62 .tobytes(),
63 raw=True,
64 )
65 g1.initializer.append(g1_const)
66 m1 = helper.make_model(g1, opset_imports=[helper.make_opsetid("", opset_version)])
67 checker.check_model(m1)
68 return m1
69
70
71def create_onnx(opset):
72 model0 = create_model0(opset)
73 model1 = create_model1(opset)
74
75 onnx.save(model0, "model0.onnx")
76 onnx.save(model1, "model1.onnx")
77
78
79if __name__ == '__main__':
80 abs_path = os.path.abspath(os.path.dirname(__file__))
81 if os.getcwd() != abs_path:
82 raise RuntimeError(f"Please run program in {abs_path}")
83
84 create_onnx(opset=11)
85
86 cmd = "poprt \
87 --config_yaml config.yaml "
88
89 os.system(cmd)
此示例会创建上示 yaml 文件需要的 onnx 模型, 并调用 PopRT 读取上述 yaml 进行模型融合, 生成 yaml 中设置的 executable.popef.
编译完成后, 可以通过 popef_dump 来查看融合模型的元数据, 它是后续运行时所需的必要信息.
命令行示例如下:
popef_dump executable.popef
成功运行上述命令后, 终端将会显示此 PopEF 文件的相关信息, 在 Anchors 关键字下, 可以看到编译后静态图的输入/输出名, 类型, 形状等信息,
其中将会有名为 index 的输入, 用于控制子图的选择.
6.6.2. 实现 PopRT Runtime 融合模型推理
要运行 PopRT 模型融合编译得到的 PopEF 文件, 需要编写程序, 通过 PopRT Runtime 进行推理.
程序示例如下:
1# Copyright (c) 2023 Graphcore Ltd. All rights reserved.
2import os
3
4import numpy as np
5import numpy.testing as npt
6
7from poprt.runtime import Runner, RuntimeConfig
8
9if __name__ == '__main__':
10 abs_path = os.path.abspath(os.path.dirname(__file__))
11 if os.getcwd() != abs_path:
12 raise RuntimeError(f"Please run program in {abs_path}")
13
14 popef_path = f"{abs_path}/executable.popef"
15
16 config = RuntimeConfig()
17 config.validate_io_params = False
18 runner = Runner(popef_path, config)
19
20 index = np.array([0], dtype=np.uint32)
21 g0_X = np.ones([1, 2], dtype=np.float32)
22 g0_Y = np.ones([1, 2], dtype=np.float32) * 2
23 g0_O = np.zeros([2], dtype=np.float32)
24
25 runner.execute(
26 {
27 "graph0/X": g0_X,
28 "graph0/Y": g0_Y,
29 },
30 {
31 "graph0/O": g0_O,
32 },
33 )
34 npt.assert_array_equal(g0_O, np.ones([2], dtype=np.float32) * 3)
35
36 index = np.array([1], dtype=np.uint32)
37 g1_X = np.zeros([1, 1], dtype=np.float16)
38 g1_O = np.zeros([1, 3], dtype=np.float16)
39
40 runner.execute(
41 {
42 "graph1/X": g1_X,
43 },
44 {
45 "graph1/O": g1_O,
46 },
47 )
48 npt.assert_array_equal(g1_O, np.array([[0.0, 1.5, 2.0]], dtype=np.float16))
此示例展示了如何运行前述生成的 PopEF 文件.
第一步, 需要创建 RuntimeConfig 实例, 配置 ModelRunner 的运行参数.
注意请务必设置 validate_io_params 为 False, 由于融合图不需要为每个输入/输出处理数据, 如设置为 True, 将会引发错误.
第二步, 创建 ModelRunner 实例, 加载 PopEF 文件, 即可将模型加载到 IPU.
第三步, 设置子图的输入/输出, 以及通过 index 指定子图, 如设置为 0 即可指定子图 0.