6.12. Auto Sharding
PopRT Auto Sharding 支持自动选择模型切分点, 实现模型并行.
6.12.1. 模型并行
PopRT 支持根据用户提供的切分点将 ONNX graph 切分到不同的设备实现模型并行, 适用于超出单个设备内存限制, 需要占用多个设备的大模型.
参考: Sharding 原理说明
Note
使用模型并行, 需要对 PopRT backend options 进行如下设置:
options.virtual_graph_mode = “manual”
options.num_ipus = 设备数量
6.12.2. Auto Sharding 原理介绍
Auto Sharding 基于 Manual Sharding 增加切分方案遍历策略.
备选点策略
Auto Sharding 会从 ONNX graph 中选择切分备选点. 选择策略是: 选取 ONNX graph 中拥有多个中间输入的 node, 中间输入不包含模型输入和常量输入.
备选点列表满足拓扑排序, 从每个备选点向其输入方向遍历找到该备选点对应的子图.
每个备选点对应一个子图, 每个子图记录对应的 内存(bytes_cost) 和 计算量(FLOPs_cost):
内存(bytes_cost): 子图中所有 node 的 initializer 输入大小的总和.
计算量(FLOPs_cost): 子图中所有 node 的 FLOPs 的总和, 通过
poprt.profile.Profiler().get_profiler()获得每个 node 对应的 FLOPs.
合并内存或计算量较小的备选点, 减少备选点数量, 提高切分方案遍历效率.
Note
切分方案遍历策略是以备选点对应的 子图 为最小单位进行遍历. 子图列表依旧满足拓扑排序.
如下图所示, 备选点是 Op1, Op2, Op7. Op1 对应的子图是 [Op1, Op0, Op4], Op2 对应的子图是 [Op2, Op5, Op6], Op7 对应的子图是 [Op7, Op3, Op8]. 从左图转化为右图进行遍历.
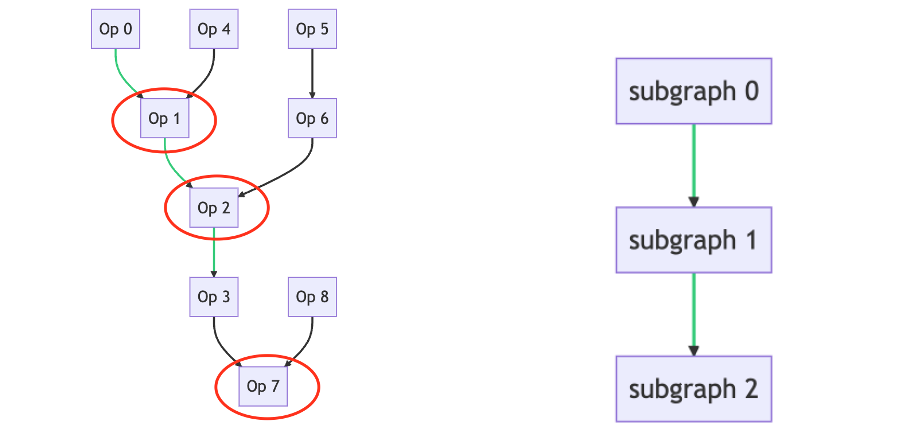
切分方案遍历策略
Auto Sharding 会从备选点中选择切分方案
初始切分: 子图列表满足拓扑排序, 直接对子图列表按子图 内存(bytes_cost) 进行切分, 保证内存均衡. 如下, 将子图列表切分成4个 子图组 , 每个 子图组 对应1个 IPU.
| subgraph, subgraph, … | subgraph, subgraph, subgraph … | subgraph … | subgraph, subgraph… |
遍历策略:
从初始方案开始遍历.
如果出现 OOM, 将按照内存调整 OOM 的 IPU 对应的 子图组, 尝试将该 子图组 中可移动子图分别放入相邻或并行 子图组 进行编译.
如果选择性能更优的切分方案, 将按照计算量对 子图组 进行平衡, 尝试将计算量最大的 子图组 中可移动子图分别放入相邻或并行 子图组 , 查找计算量更平衡的划分方案进行编译.
子图组 更新有如下情况:
子图组 起始子图, 可以分别移至 父子图组. 如下 subgraph 0 可以移至父子图组 subgraph group 0, subgraph 2 可以移至父子图组 subgraph group 1.
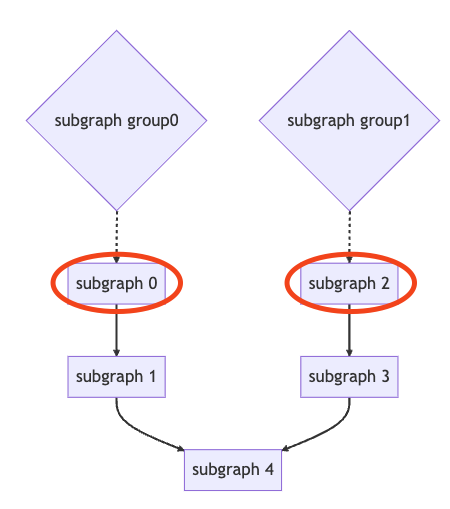
子图组 结尾子图, 可以分别移至 子子图组, 如下 subgraph 3 可以移至子子图组 subgraph group 0, subgraph 4 可以移至子子图组 subgraph group 1.
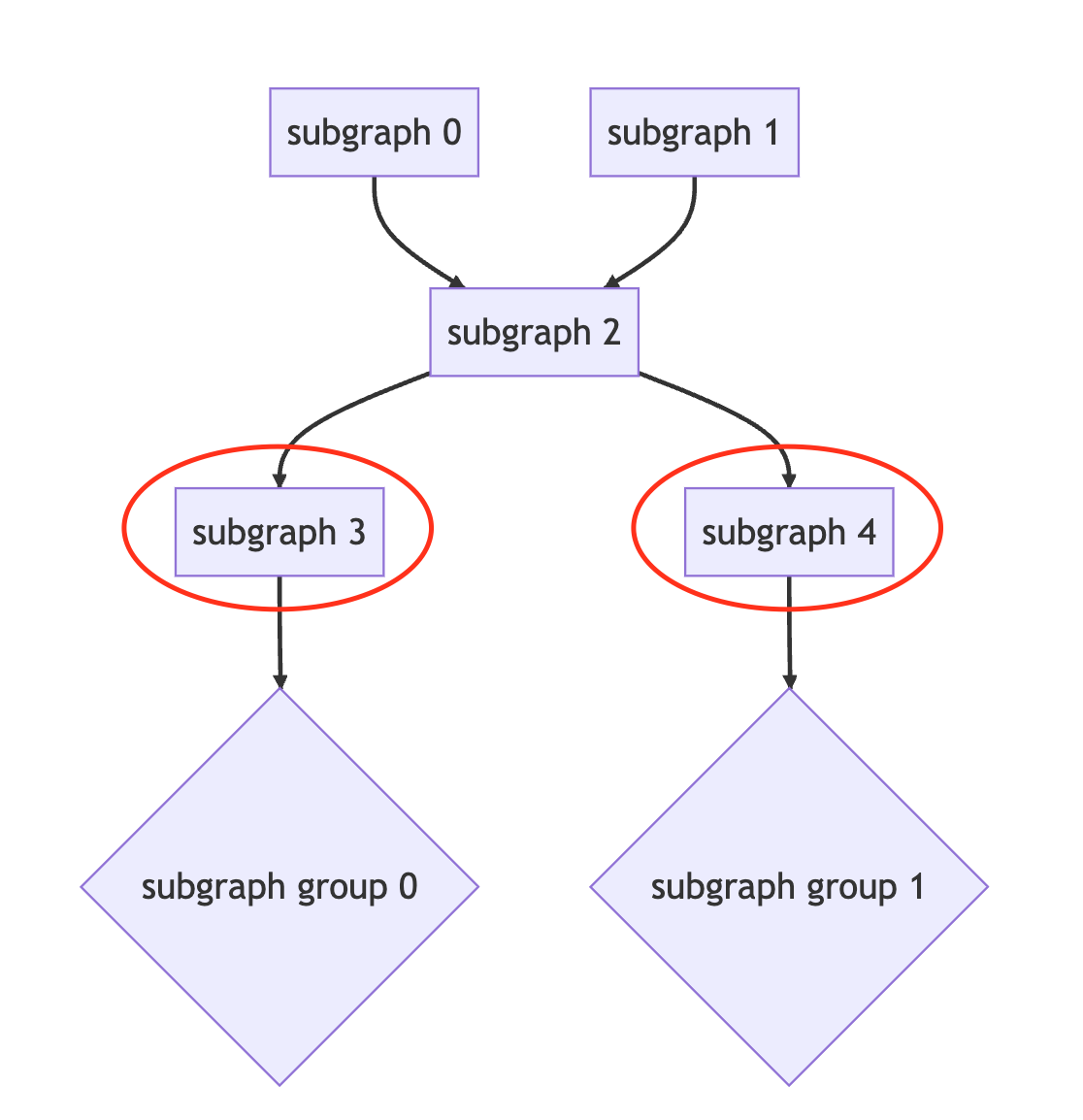
子图组 起始子图或结尾子图, 可以分别移至 并行子图组, 如下 subgraph 0, 1, 3, 4 可以移至并行子图组 subgraph group 0.
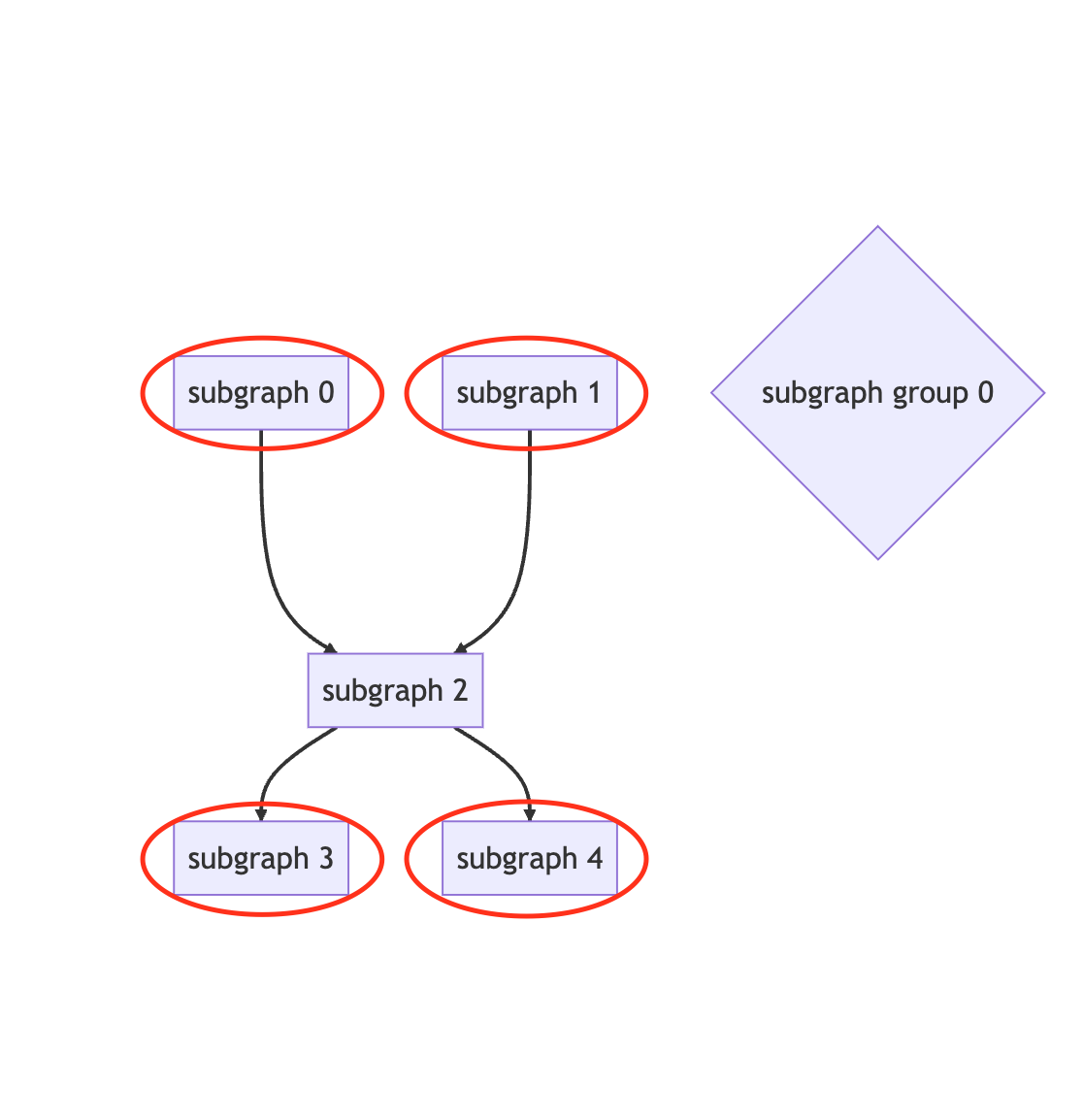
available memory proportion 调整: 如果遍历策略中, 每一个切分方案都出现 OOM, 将选择 OOM size 最小的一个切分方案尝试降低 available memory proportion 至 0.3 和 0.1 进行编译.
6.12.3. Auto Sharding 使用方法
Note
Auto Sharding 要求输入的 ONNX model 是经过 PopRT 转换的.
关于编译选项, 如果输入的 ONNX model 是 FP16 的,
partials_type默认是half.available_memory_proportion按照默认值进行切分策略遍历, 如果遍历中各切分策略均 OOM, 将按上述方式调整available_memory_proportion尝试编译. 除此之外, 不考虑其他编译选项. 用户可基于 Auto Sharding 的切分方案手动调整编译选项.因为没有考虑切分方案 Profiling 的实际表现进行调整, Auto Sharding 尝试遍历编译策略找到的切分方案可能是一个局部有效解, 不一定是全局最优解. 用户可以基于 Auto Sharding 选出的切分方案, 使用 Manual Sharding 手动调整切点.
Auto Sharding 耗时可能较长, 和编译耗时成正比.
参数介绍
Auto Sharding 工具位置: auto_sharding.py .
--input_model ${INPUT_MODEL}: 输入的 ONNX model.--num_ipus ${NUM_IPUS}: 指定 IPU 数量.--output_model ${OUTPUT_MODEL}: 输出的 ONNX model, 如果不设置, 会默认指定为${input_model}.auto_sharded.onnx.--optimal_perf: 是否开启性能选优. 如果不开启, 将在找到第一个成功编译的切分方案后停止遍历, 如果开启, 将在遍历所有切分方案后选择性能最优的切分方案.--num_processes ${NUM_PROCESSES}: 并行编译的进程数, 默认为2.
举例
不开启性能优化. 将模型切分到2个 IPU, 遍历切分方案均 OOM, 选择 OOM size 最小的切分方案尝试
available_memory_proportion=0.3, 编译成功.
python auto_sharding.py --input_model ../debug/deberta.onnx.optimized.onnx --num_ipus 2
...
[Success] Compile successfully available_memory_proportion 0.3 and solution:
Sharding nodes: Device 0 - ['Add_938']
[Success] The latency 336.2899446487427 ms, tput 2.9736244449548064
[Success] Save the sharded model to ../debug/deberta.onnx.optimized.onnx.auto_sharded.onnx
开启性能优化. 将模型切分到2个 IPU, 遍历后返回性能最优解.
python auto_sharding.py --input_model=vit_l_16_16.onnx.optimized.onnx --num_ipus=2 --optimal_perf
...
[Success] The optimal solution:
Sharding nodes: Device 0 - ['/encoder/layers/encoder_layer_11/Add_1']
[Success] The optimal latency 2.712721824645996 ms, tput 368.6334481164495
[Success] Save the sharded model to vit_l_16_16.onnx.optimized.onnx.auto_sharded.onnx