6.5. CPU Packing
6.5.1. 背景
IPU 运行的是静态图, 每次处理固定大小的输入数据. 如果输入长度是不固定的, 就需要进行额外的补0操作, 无法有效发挥 IPU 的数据处理能力. CPU pack 是通过 PackRunner 实现的, 专门为动态 sequence length 设计, 用户请求被 Pack 之后极大的减少了补0的数量, 再配合模型修改实现等价变换, 能够有效发挥IPU数据处理效率.
6.5.2. 功能模块介绍
Pack 实质上是在固定时间内积攒用户不固定长度的请求, 然后把数据打包在一起, 一次性发给 IPU.
1. 超时处理
为了能够一次性发给 IPU 更多的有效数据, 需要在一定时间段积攒 batch. 另外, 超时的设置是为了不让用户请求等待时间超过设定值.
2. 用户数据预处理
如果用户数据中已经进行了补0填充, 在预处理时会根据请求中的 mask 数据将用户填充的0数据去除.
3. 数据累积
Pack 内部维护了一个队列, 用户请求将被入队列, 在超时模块发出请求或者 Pack 内数据达到最大值(达到最大条数或者即将超过模型输入大小)时 PackRunner 会把积攒的请求发往 IPU(出队列).
4. Pack 后处理
IPU 运算完成后会通知 pack 程序取数据, 将输出重新拷贝回用户地址, 用户程序得到的即是与输入相对应的结果, 无需做特殊的处理. pack 在做拷贝数据的时候分两种情况
网络中插入了 unpack 算子, 这个时候输出长度固定, 按照固定长度拷贝回来即可.
网络中没有 unpack 算子, 这里默认拷回的输出长度等于输入数据的有效长度(输入去除了用户 pad 的长度).
Pack功能模块示意图
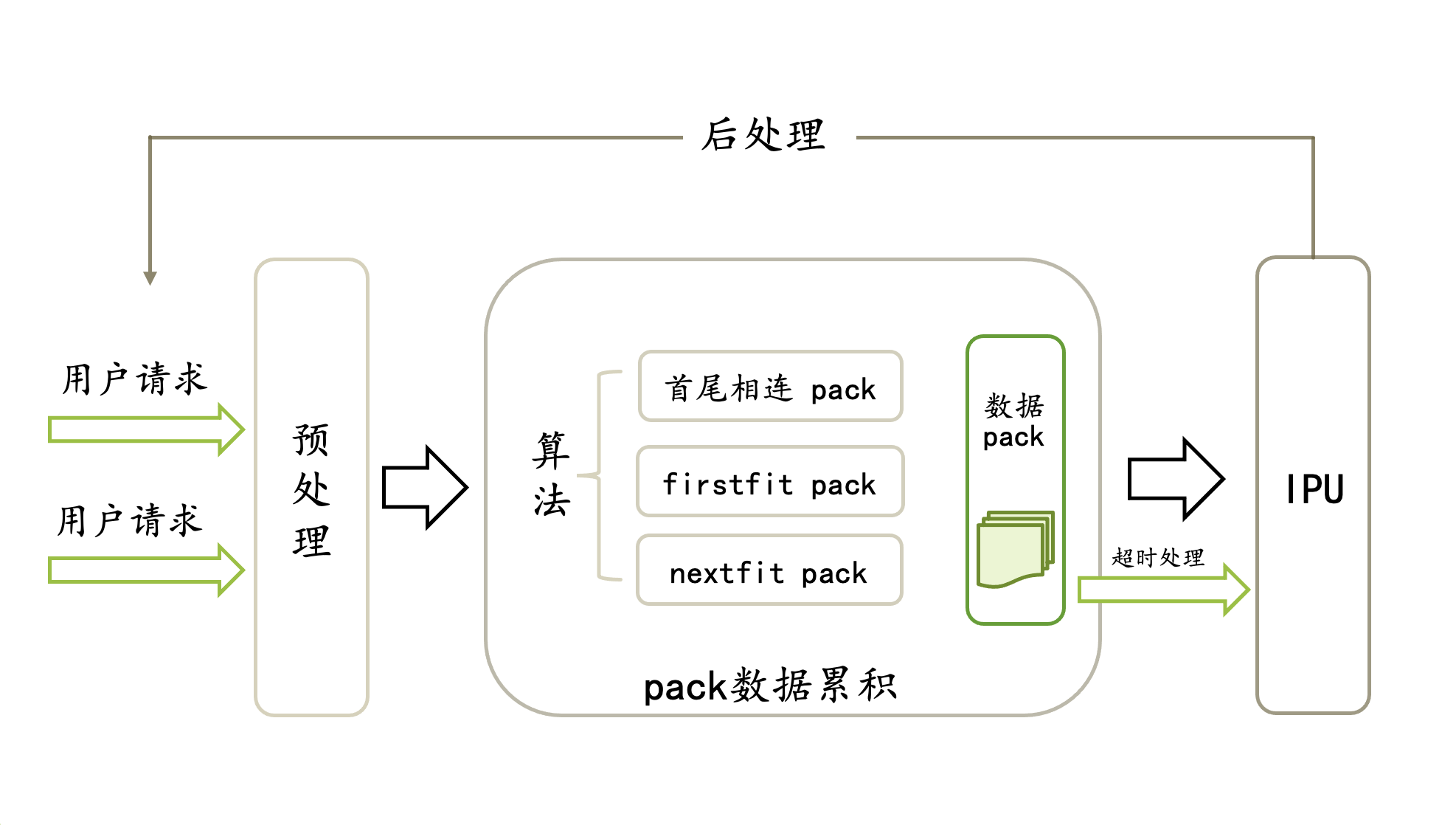
6.5.3. Pack 算法
当前 cpu pack 支持首尾相连的 pack 方法, FirstFit pack 方法, NextFit pack 方法.
Pack 内置了下面三种限制
Pack 的数据总条数不能超过设置的 maxValidNum
Pack 的总数据长度不能超过编译时模型输入的最大长度
Pack 的第一条数据与最后一条数据到来的时间间隔不能超过用户设置的最大的值
1. 首尾相连的 pack 方法
本方法是将数据首尾相连的拼接在一起, 直到达到设定的最大条数或者即将超出了输入的最大值(编译模型时输入大小), 首尾相连的 pack 数据可以跨行, 需要在网络中插入 unpack repack 算子.
2. FirstFit pack 方法
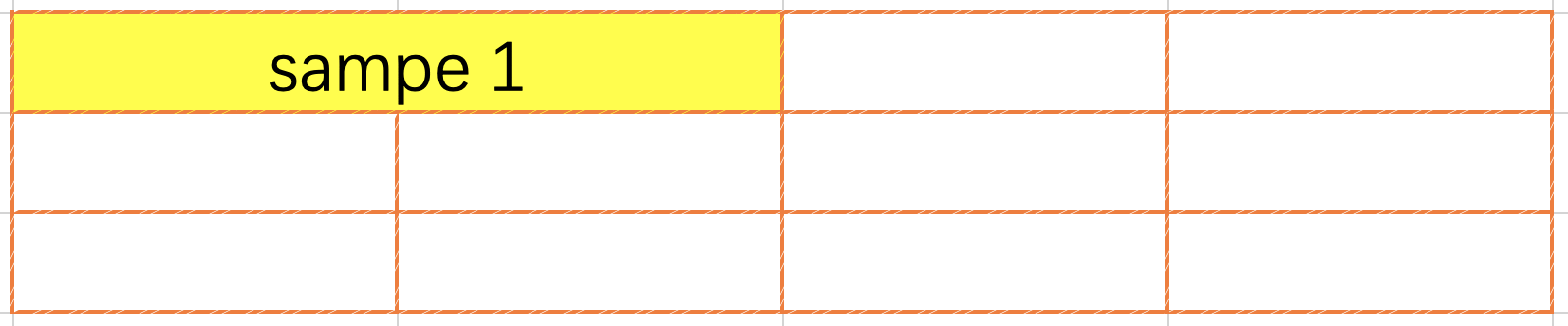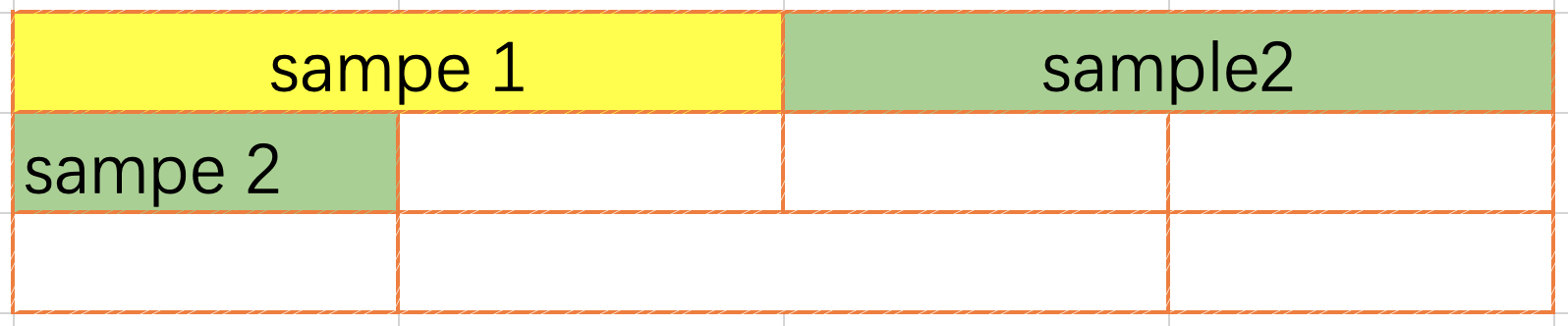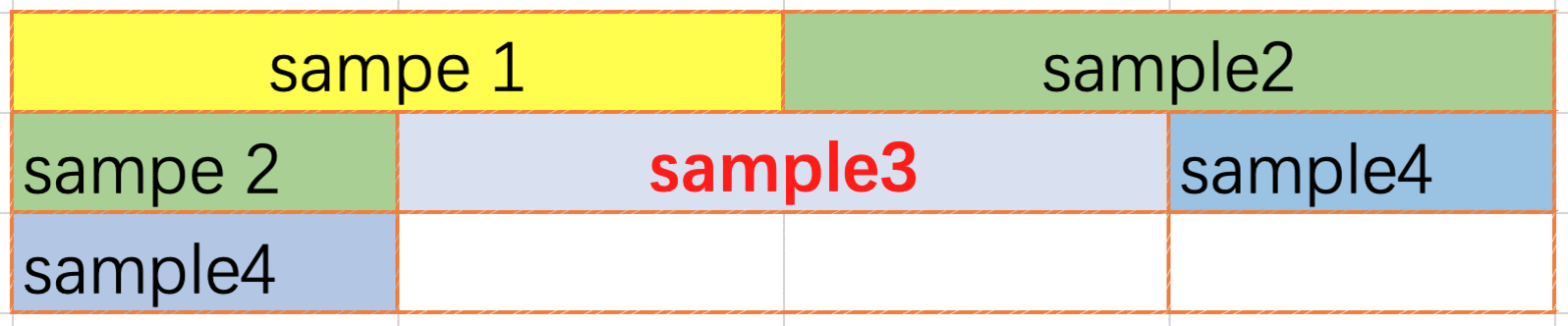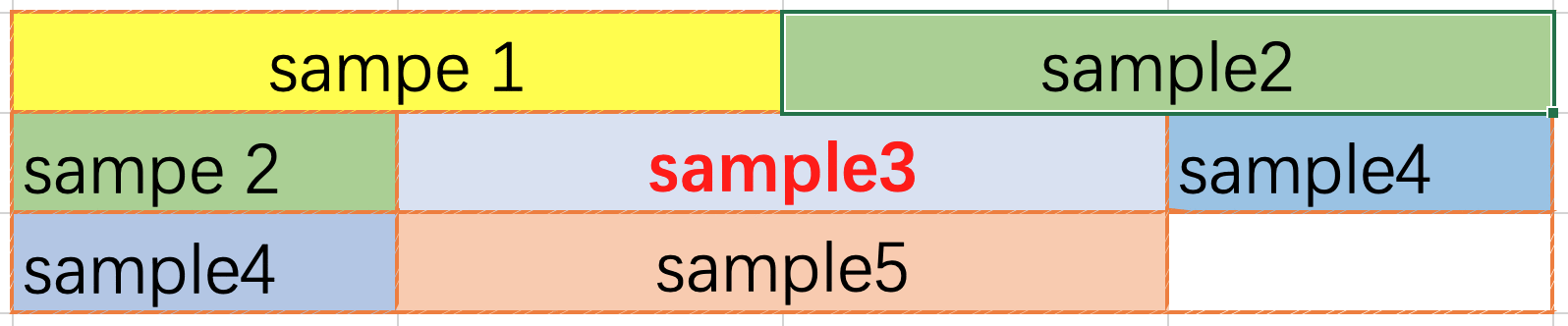
FirstFit pack 属于行内 pack, 也就是数据不可以跨行, 用户请求到来的时候会从第一行开始扫描, 直到找到一行可以放置下本条数据, 如果无法找到则另起一行. 根据网络要求可能会需要在两条数据之间插入若干个0作为分隔符, 行内第一条数据之前不需要分割符号. FirstFit 虽然改变了用户请求在 pack 内的相对顺序, 因内置程序对结果顺序进行了调整, 对用户而言结果顺序与输入顺序是一致的. 与 NextFit 相比 FirstFit 提升了空间利用率.
3. NextFit pack 方法
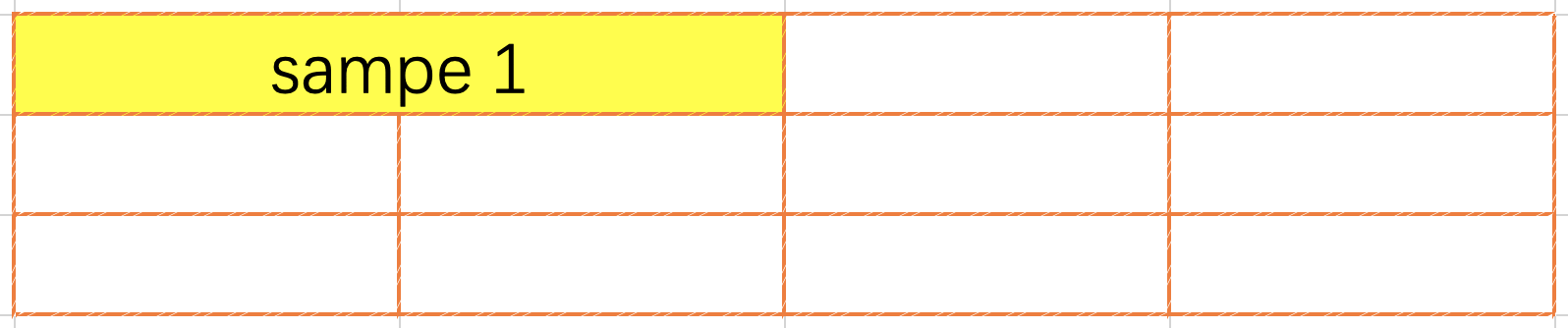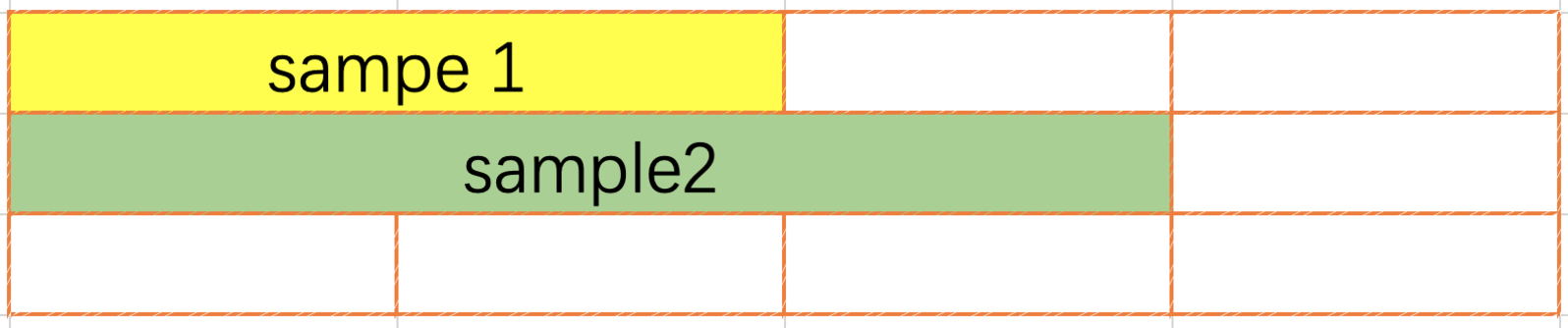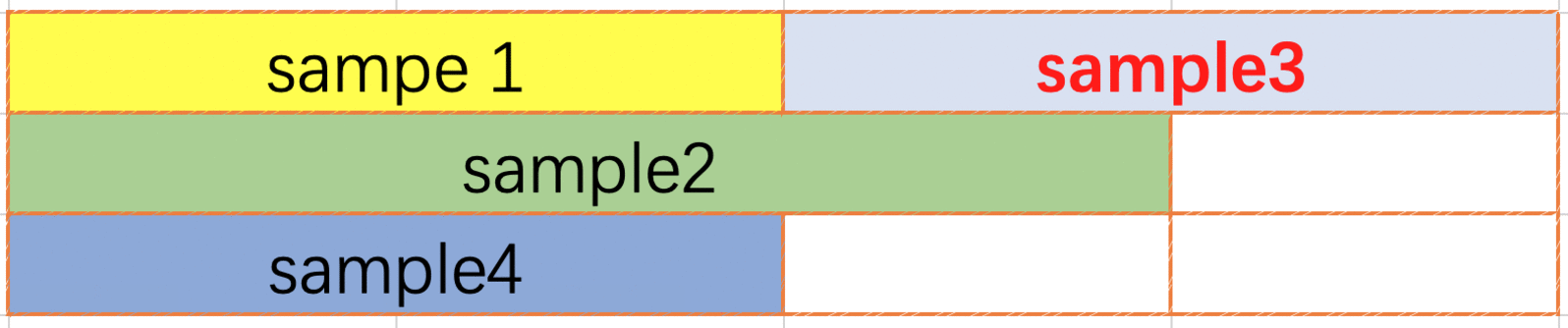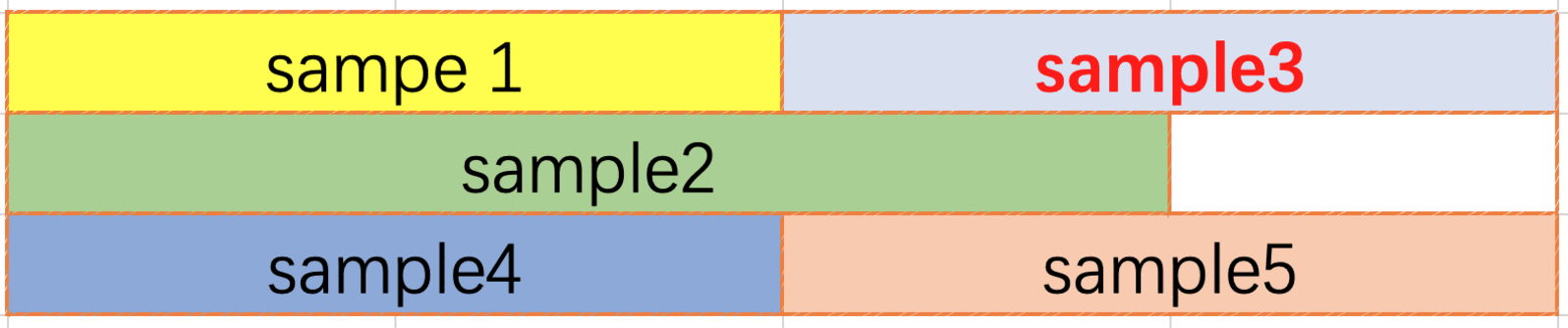
NextFit pack 也是一种行内 pack, 数据不可以跨行. 用户请求到来的时候, 从上一条数据的末尾开始扫描直到找到一行可以放得下本条数据, 如果找不到则另起一行. 同样的, pack 的总数据长度不可以超过编译时输入的的最大长度. 与 FirstFit 一样, 可能需要在两条数据之间插入分隔符.

6.5.4. 示例
PopRT 提供了两个端到端例子用以阐释如何在 IPU 上使用 pack, 每个例子都包含了上面介绍的三种 pack 算法以及相应的性能数据.
bert 的 pack 示例目录 packed_bert_example
deberta 的 pack 示例目录 packed_deberta_example
使用方法详见相应目录内 README.md