5.1. 使用 FP8 数据类型
5.1.1. IPU FP8 类型介绍
FP8 顾名思义即 8bit 的 float 数据类型, 内存占用为 FP32 的 1/4, FP16 的 1/2, 与 INT8 一样. IPU 支持两种 FP8 数据类型: F8E4M3 和 F8E5M2.
FP8 二进制编码如下表:
E4M3 |
E5M2 |
|
Exponent bias |
8 |
16 |
Max normal |
S.1111.110 = 1.75 * 2^8 |
S.11111.10 = 1.10 * 2 ^ 16 |
Min normal |
S.0001.000 = 1.0 * 2 ^ -6 |
S.00001.00 = 1.0 * 2 ^ -14 |
Max subnorm |
S.0000.111 = 0.875 * 2 ^ -6 |
S.00000.11 = 0.75 * 2 ^ -14 |
Min subnorm |
S.0000.001 = 0.125 * 2 ^ -6 |
S.00000.01 = 0.25 * 2 ^ -14 |
从表中可以看出, E4M3 的表示范围更小, 但是精度略高于 E5M2. 此外, 与 FP32/FP16 相比, FP8 的动态范围要小得多, 为了扩大表达范围, FP8 还支持通过一个额外的 scale 参数来调整表示范围, scale 越大, 表示范围越大, 精度越低, scale 越小, 表示范围越小, 精度越高.
更多关于 FP8 的信息参考 8-bit Numerical Formats for Deep Neural Networks.
5.1.2. FP8 量化介绍
模型量化在实际应用中很常见, 其中 INT8 量化更是被广泛应用, 这是将模型中所有的输入和参数转换为 INT8 格式同时只损失很少精度的技术, 可以在降低内存占用的情况下加快推理速度, 主要包括后训练量化和量化训练这两种, 量化对象为权重和输入, 它们都会引入额外的数据还原层, 会增加计算量, 不像 FP32 转 FP16 那样直接.
FP8 量化的目的也是最大限度将低精度转换后的损失, 转换过程跟 FP32 转 FP16 一样直接, 如果模型全为 FP8, 无需修改模型结构, 直接将输入和参数转换为 FP8 即可, 如果是 FP8 与 FP16 的混合精度模型, 只需要在对应地方加上 Cast. FP8 量化会确定一组 scale 和 format 参数, 满足精度损失尽可能低的要求. 目前 IPU 还未支持 FP8 的量化训练, 因此这里只介绍后训练量化, 包括对权重和输入的量化.
关于权重量化, IPU 支持的 FP8 算子暂时只包括 Conv/MatMul/Cast, 所以会把 FP16/FP32 模型对应算子的权重取出并做 FP8 转换, 转换时会为每一组权重设置不同的 scale 和 format 参数, 然后将转换后的权重与 FP16/FP32 的权重计算损失, 损失最小的那组对应的 scale 和 format 就为该层权重最佳的 FP8 参数, 之后按同样的方式处理下一组权重. 整个转换过程在 CPU 上进行, 损失包括 mse/mae/snr/kld/cos_dist, 量化时指定其中一种即可.
关于输入量化, 量化原理与权重量化一致, 处理方式有些许区别. 由于每个 FP8 算子的输入是未知的, 无法直接对输入做量化, 所以需要事先给定一些校验数据进行推理, 然后记录每个 FP8 算子的输入, 接着要做的事情就是和权重量化一样, 通过遍历的方法找到 FP16/FP32 的输入与 FP8 输入损失最小的那组 scale 和 format.
5.1.3. FP32 模型转 FP8 模型的流程
对于 MatMul 和 Conv 等计算密度高的算子, FP8 类型比 FP16 类型有更高的算力, 因此把模型从 FP32/FP16 转换成 FP8, 能够提高模型的吞吐, 降低模型的延时. 另外由于 IPU 是把整个模型放到片上运行, FP8 类型的 Tensor 相比 FP32/FP16 类型的 Tensor, 需要的存储空间更小, 因此 IPU 能够跑更大规模的模型, 或者支持更大的 Batch Size.
模型从 FP32/FP16 类型转成 FP8 类型, 是指把模型中支持 FP8 类型的算子替换成 FP8 类型, 然后该算子对应的权重 Tensor 转换为 FP8 类型的 Tensor. 由于目前 IPU 只有 Conv 和 MatMul 算子支持 FP8 类型的计算, 因此 PopRT 工具中的 FP8 转换其实是混合精度模型的转换, 即只把 Conv 和 MatMul 算子转成 FP8, 其它算子保持原来的类型.
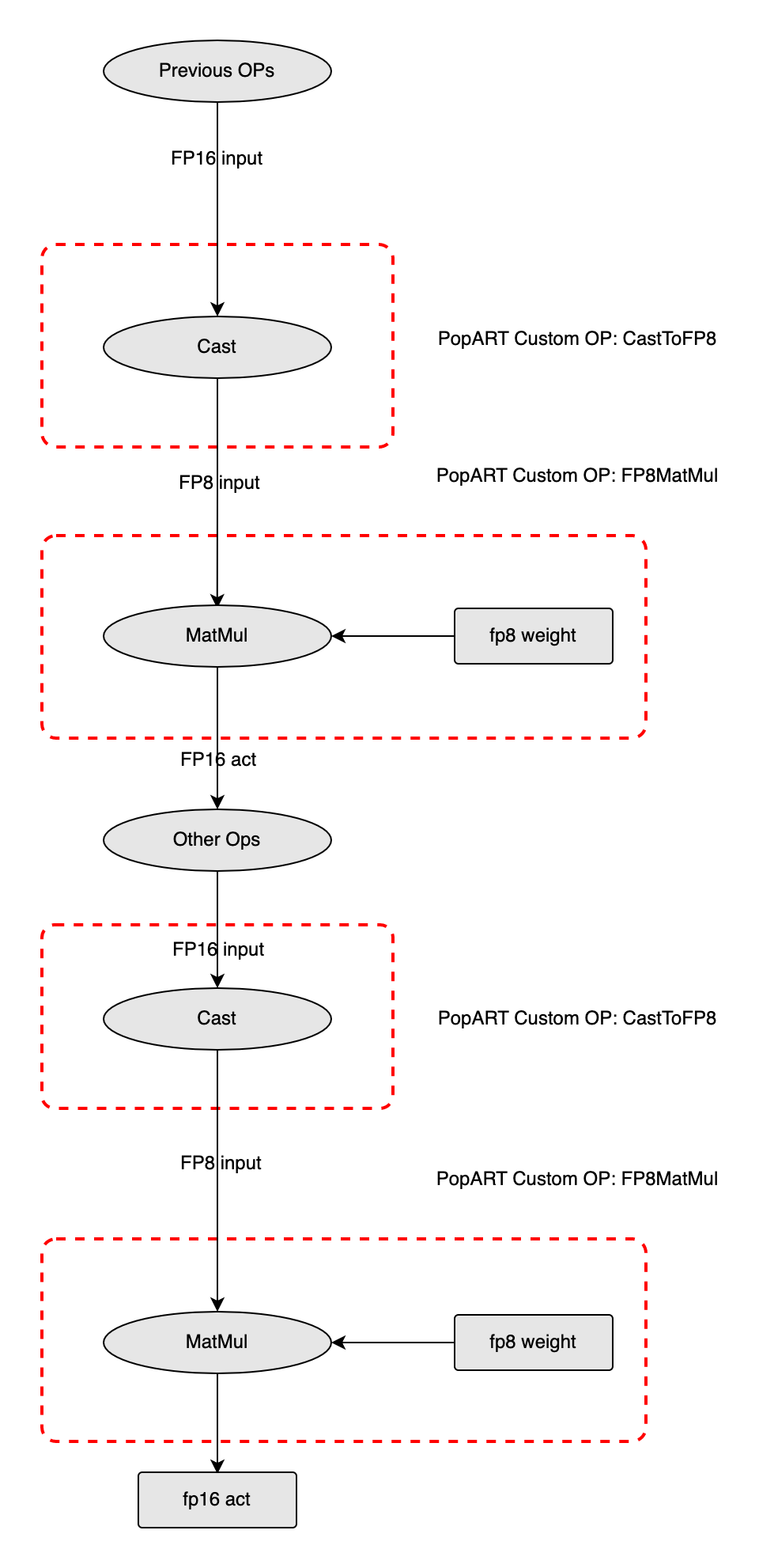
这里通过举例来说明如何将一个包含两个 MatMul 的 onnx 模型转换为 FP8 格式. 在 MatMul 之前, 其他 OP 的输出是 FP16 格式, 需要在这些 OP 后面添加一个 Cast 节点将其转换为 FP8. 同样的, MatMul 的另外一个权重输入也需要转换为 FP8, 但是权重的 FP8 转换不是在模型中通过 Cast 进行, 而是预先在 CPU 上对 onnx 模型中的权重进行 FP8 转换, 这样便能省去权重部分的 Cast, 提高推理效率. 转换完成之后便开始执行第一个 FP8 MatMul, 输出的类型为 FP16, 然后在执行第二个 MatMul 时, 输入和权重做同样的 FP8 转换, 依次类推, 直至完成整个推理过程.
5.1.4. FP8 模型转换工具使用方法
FP8 模型转换工具目前包含两种使用方式, 一种是用默认的 scale 和 format 进行快速转换, 值分别为 0 和 F143, 这样可以很快的验证模型是否能成功转换为 FP8, 更加方便的验证 FP8 模型的速度. 另一种是启用 FP8 的量化工具进行转换, 这种方式会消耗一些时间来计算最佳的 scale 和 format, 可以让模型的精度损失更低, 还能得到不同参数下各层的误差情况, 方便进行精度的进一步调试.
以 ResNet50 为例对两种使用方式进行介绍.
在下载模型之前需要先安装依赖包, 命令如下:
pip install torch==1.10.0
pip instal torchvision==0.11.1
ResNet50.onnx 下载和转换脚本:
dummy_input = torch.randn((1, 3, 224, 224))
model = torchvision.models.resnet.resnet50(pretrained=True).eval()
torch.onnx.export(
model,
dummy_input,
'ResNet50.onnx',
input_names=["input"],
output_names=["output"],
opset_version=11,
)
快速转换的命令如下:
poprt \
--input_model ResNet50.onnx \
--output_model ResNet50_FP8.onnx \
--input_shape input=1,3,224,224 \
--precision fp8 \
--fp8_skip_op_names Conv_0,Conv_8,Gemm_121 \
--fp8_params F143,F143,-3,-3 \
--convert_version 11
其中 fp8_skip_op_names 和 fp8_params 是用于调整精度的参数, 前者可以指定哪些层保留为 FP16 数据类型, 后者用于指定输入和权重的 format 和 scale, 如果不设置, 工具会将模型所有的 Conv/MatMul/Gemm 转换为 FP8, format 和 scale 会使用默认值.
此外, 工具还支持用 fp8 存储权重, 用 fp16 执行推理, 该方式相比 fp16 模型可以在少量增加延时的情况下显著降低内存的占用, 转换方式与上述的 fp8 基本无异, 只需将 precision 参数改为 fp8_weight 即可.
量化转换的命令如下:
poprt \
--input_model ResNet50.onnx \
--output_model ResNet50_FP8.onnx \
--input_shape input=1,3,224,224 \
--precision fp8 \
--quantize \
--quantize_loss_type kld \
--num_of_layers_keep_fp16 3 \
--data_preprocess calibration_dict.pickle \
--precision_compare \
--convert_version 11
其中 quantize 参数表示开启量化转换, 此时需要额外传入用作数值校验的输入数据. num_of_layers_keep_fp16 用于将损失为 topk 大的层保留为 FP16, 以进一步提高模型精度.
例如 ResNet50 的输入名为 input, 输入数据为 ImageNet, 可以从 ImageNet 的测试集中随机取出约 50 张图片制作校验集, 校验集的 shape 为 50*3*224*224, 然后以字典的形式 {input: ndarray} 保存为 pickle 文件. 需注意如果模型有预处理过程且没有包含在网络中, 校验数据要做完预处理之后再保存, 确保其与模型的输入能够匹配.
quantize 完成之后会得到一个 quantize.log 的文件, 该文件记录着 FP8 算子输入和权重部分不同 scale 和 format 下的损失, 同时也会给出损失最小的那组 scale 和 format, 这组参数即是量化后的 FP8 模型用到的参数, 此外, 当 quantize_loss_type 不为 kld 时, 还会额外记录量化前后及量化噪声的均值/方差/偏度/峰度等信息.
如果设置 precision_compare, 会计算 FP16 模型与 FP8 模型中间层的输出损失, 结果保存在 precision_compare.log 中, 这可用于精度进一步调试, 各个指标的含义及调试建议如下:
MSE: 平均均方误差, 用于计算原始数据与量化数据间的误差平方和的均值, 越接近 0 越好, 值大小受数据本身大小和数据量的影响, 需结合数据本身的情况一起考虑.
MAE: 平均绝对误差, 用于计算原始数据与量化数据间的绝对值误差的均值, 越接近 0 越好, 同样受数据本身大小和数据量的影响, 需结合数据本身的情况一起考虑.
SNR: 信噪比, 用于计算原始数据与量化数据间的误差平方和与原始数据平方和的比值, 越接近 0 越好, 消除了数据本身大小和数据量的影响, 可适当对比各层间该值的大小来判断误差情况.
Cosine Distance: 余弦距离, 用于计算原始数据与量化数据展开为一维后的夹角大小, 越接近 0 越好, 不受数据本身大小和数据量的影响, 且范围在 0 与 1 之间, 这些特性使得它成为非常直观且重要的评价指标, 可适当对比各层间该值的大小来判断误差情况, 有些层的差异可能会达到一个数量级.
Noise Skewness: 用于计算原始数据与量化数据间的差值的偏度, 衡量分布的不对称性, 若偏度大于 0, 则分布右偏, 若偏度小于 0, 则分布为左偏, 同时偏度的绝对值越大, 说明分布的偏移程度越严重.
Noise Kurtosis: 用于计算原始数据与量化数据间的差值的峰度, 衡量分布的陡峭或者平滑状况, 若峰度接近 0, 分布的峰态服从正态分布, 若峰度大于 0, 分布越陡峭, 峰度小于 0, 分布越矮胖.
Noise Hist: 用于统计原始数据与量化数据间的差值的直方图, 直方图被分为 32 个 bin 区间, 衡量数据总体的分布情况.
precision_compare.log 给出了原始数据, 量化数据以及这两者间误差的 mean/std/min/max/skewness/kurtosis/histogram 这些指标, 它们用于刻画数据总体的分布形状, 帮助用户从统计的角度去比较量化前后的数据差异.
5.1.5. FP8 模型转换精度调试经验
在精度仍较差的情况下, 可以尝试以下方法:
对于快速转换, 如果是 CV 类模型, 建议将首个 Conv 和最后的 MatMul 保持为 FP16, 如果是 NLP 类模型, 建议将最后的 MatMul 保持为 FP16. format 使用 F143, 在推理过程中 E4M3 的 FP8 格式精度更高, scale 选择在 -5 到 0 之间的整数值, 可以逐个进行尝试选取精度最高的那一个.
对于量化转换, 校验集需从真实的数据中选取, 数据量不宜过大, 否则量化过程会很漫长, 例如 ResNet50, 可以选择 20 张左右的图片做为校验集, 实际情况需根据模型大小自行调整, 如果量化速度过慢, 可适当降低数据量大小.