5.3. 使用 Dynamic Batch Size
5.3.1. 背景
由于 IPU 仅支持静态图, 在模型编译阶段需要指定固定的 batch size. 而在实际推理过程中, 输入数据的 batch size 通常情况下是不固定的. PopRT 通过设置 timeout_ns 和 batching_dim 来支持任意 batch size 大小的输入数据.
timeout_ns: PopRT 等待数据组成 PopEF 模型所要求的 batch size 大小的超时时间. 默认设置为5ms.batching_dim: 模型按照哪一个维度扩展 batch size 数据. 默认值为0xFFFFFFFF, 表示未开启 dynamic batch size 的功能.
IPU 中每次推理数据的处理是按照加载模型的 batch size 大小为单位进行的. 例如, Fig. 5.3 中模型的 shape 大小为 [4, 2], 并且 batch size 的维度是 0, 即每次处理 batch size 为 4 的数据. 当输入数据的 batch size 是模型 batch size 的 N (N 为大于等于1的整数) 倍时, 会在 IPU 上经过 N 次推理后返回推理结果. 这种情况下, 是不需要等待 timeout_ns 超时的.
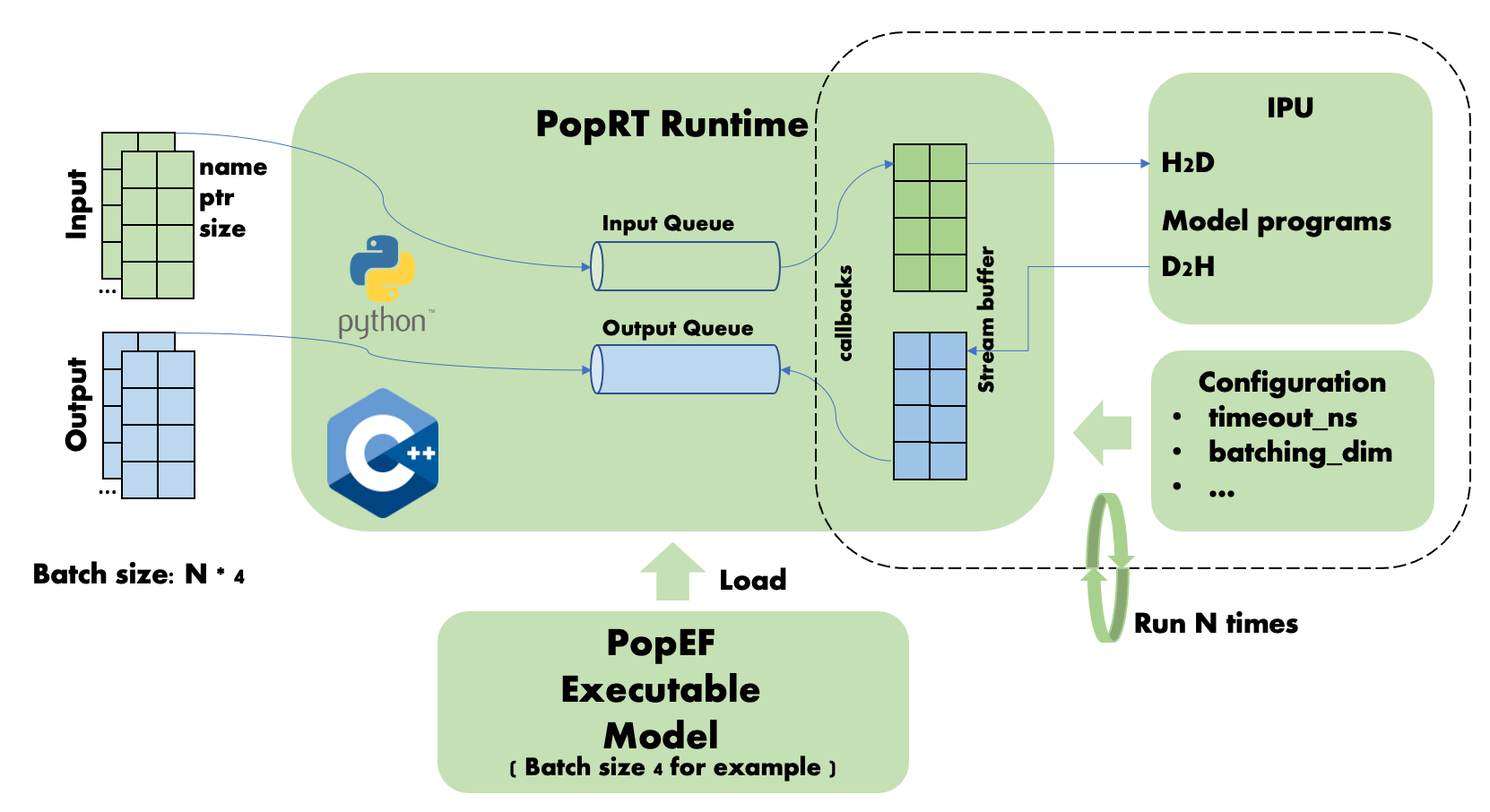
Fig. 5.3 Dynamic Batch Size
如果输入数据的 batch size 是模型 batch size 的 N (N 为大于等于0的整数) 倍加上 M (M 为小于等于 batch size 的整数) 时, N 倍的数据处理与 Fig. 5.3 中的处理相同, 而小于模型 batch size 的数据 M 则需要等待 timeout_ns 设置的超时时间. 如果在这个时间内有后续的一组或多组数据与数据 M 合并后达到 batch size 的大小, 则进行一次推理得到结果. 如果直到超时也未达到 batch size 的数据大小, 则会将空缺的部分设置为 0, 并开始进行推理得到结果. 如 Fig. 5.4 中所示, batch size 为 1 和 2 的两个请求合并后, 达到超时的时间, 剩下的 batch size 为 1 的数据被设置为 0.
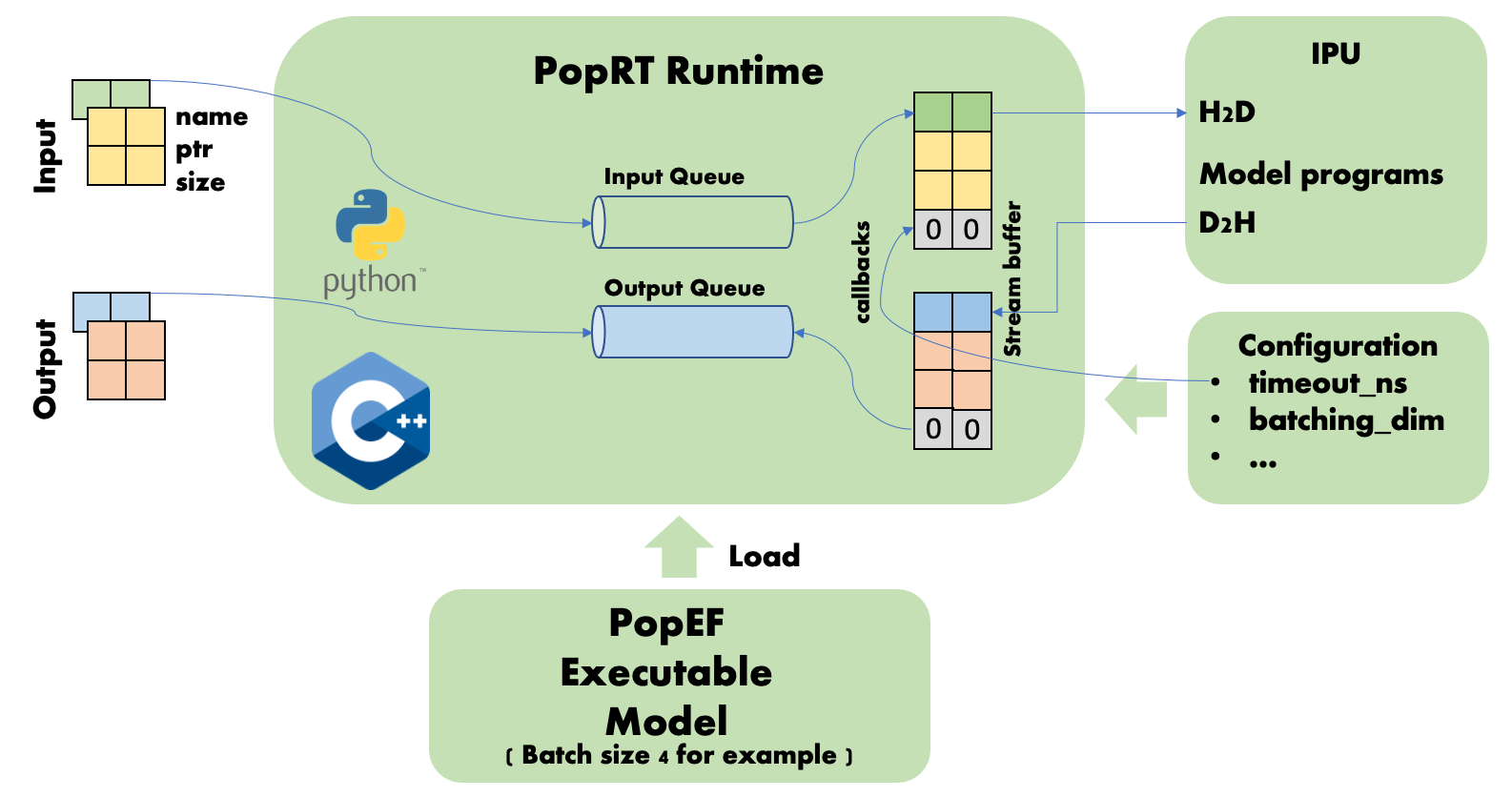
Fig. 5.4 Dynamic Batch Size Timeout
动态 batch size 的功能对于用户程序来说是透明的, 用户无需关心当前 IPU 中加载模型的 batch size 大小, 按照应用的需求发送推理请求数据就可以了.
5.3.2. 示例
Listing 5.2 中是动态 batch size 的示例代码. 示例中创建一个输入 shape 为 [4, 2] 的模型, 其 batch size 为 4. 应用程序分别使用 batch size 为 1, 4, 7 的数据进行推理, 无需考虑加载模型的 batch size 大小.
1# Copyright (c) 2023 Graphcore Ltd. All rights reserved.
2import datetime
3
4import numpy as np
5import numpy.testing as npt
6import onnx
7
8from onnx import helper
9
10from poprt import runtime
11from poprt.compiler import Compiler
12from poprt.runtime import RuntimeConfig
13
14
15def default_model():
16 """Create a test model."""
17 TensorProto = onnx.TensorProto
18 add = helper.make_node("Add", ["X", "Y"], ["O"])
19 graph = helper.make_graph(
20 [add],
21 "test",
22 [
23 helper.make_tensor_value_info("X", TensorProto.FLOAT, (4, 2)),
24 helper.make_tensor_value_info("Y", TensorProto.FLOAT, (4, 2)),
25 ],
26 [helper.make_tensor_value_info("O", TensorProto.FLOAT, (4, 2))],
27 )
28 opset_imports = [helper.make_opsetid("", 11)]
29 original_model = helper.make_model(graph, opset_imports=opset_imports)
30 return original_model
31
32
33def compile(model: onnx.ModelProto):
34 """Compile ONNX to PopEF."""
35 model_bytes = model.SerializeToString()
36 outputs = [o.name for o in model.graph.output]
37 executable = Compiler.compile(model_bytes, outputs)
38 return executable
39
40
41def run(executable):
42 """Run PopEF."""
43 config = RuntimeConfig()
44 config.timeout_ns = datetime.timedelta(microseconds=300)
45 config.batching_dim = 0
46 model_runner = runtime.ModelRunner(executable, config)
47 batch_sizes = [1, 4, 7]
48 for batch_size in batch_sizes:
49 inputs = {}
50 inputs['X'] = np.random.uniform(0, 1, [batch_size, 2]).astype(np.float32)
51 inputs['Y'] = np.random.uniform(0, 1, [batch_size, 2]).astype(np.float32)
52
53 outputs = {}
54 outputs['O'] = np.zeros([batch_size, 2], dtype=np.float32)
55 model_runner.execute(inputs, outputs)
56 expected = inputs['X'] + inputs['Y']
57 npt.assert_array_equal(
58 outputs['O'],
59 expected,
60 f"Result: outputs['O'] not equal with expected: {expected}",
61 )
62 print(f'Successfully run with input data in batch size {batch_size}')
63
64
65if __name__ == '__main__':
66 model = default_model()
67 executable = compile(model)
68 run(executable)
Download dynamic_batch_size.py
运行示例得到如下的输出信息:
Successfully run with input data in batch size 1
Successfully run with input data in batch size 4
Successfully run with input data in batch size 7