5.4. 使用 Packing
5.4.1. 背景
当前 IPU 只支持静态图, 模型的输入 shape 需要是固定的, 动态 shape 会导致模型重新编译. 但在实际应用中, 尤其是自然语言处理类型的应用, 模型输入 sequence length 往往是动态的. 这种情况下, 常规的处理方法是将这些变长数据都先 pad 到 max sequence length, 然后再输入到模型. 然而这种方法会带来很多无效计算, 导致算力的实际利用率低下. 在 IPU 上, 可以使用 Packing 来支持 dynamic sequence length, 提高算力利用率.
5.4.2. Packing 及 Unpacking
这里通过例子来说明什么是 Packing 及 Unpacking. 假设模型输入长度最大是 8, batch size 是 4, 当前有 7 个不同长度的 batch size 为 1 的 request, 长度从 1 到 7, 0 表示 pad 的无效数据, 则 Packing 及 Unpacking 如下图所示:
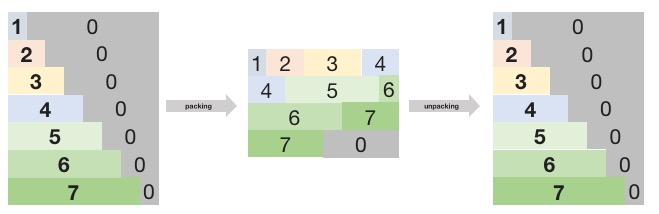
Fig. 5.4 Packing 及 Unpacking
5.4.3. Transformer-based NLP Models
自 2017 年被提出以来, Transformer 结构应用领域不断扩展, 从最初的 NLP 扩展到今天的 ASR/CV/DLRM 等领域. Transformer 包含 Encoder 和 Decoder 部分, 本文只关注 Encoder 部分. Transformer Encoder 结构如下图所示:
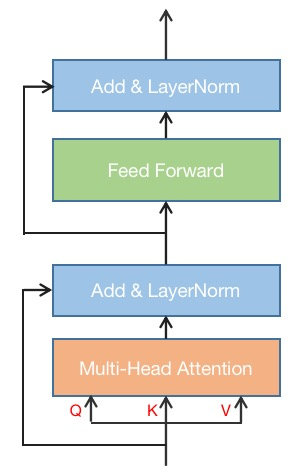
Fig. 5.5 Transformer Encoder
以 Bert 为例, Transformer Encoder 的输入 shape 通常为 (batch_size, seq_len, hidden_size). 在 Encoder 中, 除 Multi-Head Attention 模块外, 其它模块的计算都只在最后一个维度进行, 因此针对这些模块, 可以通过 Packing 减少无效计算; 而 Multi-Head Attention 模块因为需要计算 token 之间的相关性, 在不修改 mask 的情况下, 必须在 Unpacking 之后进行计算, 在 Multi-Head Attention 计算完成之后重新 Packing. 计算流程可以用如下伪代码表示:
packed_input from host
activation = packed_input
for encoer in encoders:
Unpacking
Attention
Packing
Add & LayerNorm
Feed-Forward
Add & LayerNorm
Update activation
Unpacking
unpacked_output to host
5.4.4. 如何使用 Packing
本节以 Bert-Base-Squad 为例进行说明, 本文使用的 OS 为 Ubuntu 20.04, Python 3.8.15. 本文完整示例参考 examples/packed_bert_example.
下载模型
在下载模型之前需要先安装依赖包, 命令如下:
pip install torch==1.10.0
pip install transformers[onnx]==4.25.1
下载模型的命令如下:
python -m transformers.onnx --model=csarron/bert-base-uncased-squad-v1 . --feature question-answering
转换模型
通过上面命令下载的模型, 输入中不包含 position_ids, 而在 IPU 上使用 Packing 的时候, 需要首先在 host 端将输入进行 Pack, 因此需要将 position_ids 加到模型的输入上. 代码如下:
1# Copyright (c) 2023 Graphcore Ltd. All rights reserved.
2import argparse
3import copy
4import os
5
6import onnx
7
8# Download model from huggingface
9# - python -m transformers.onnx --model=csarron/bert-base-uncased-squad-v1 . --feature question-answering
10# reference: https://huggingface.co/csarron/bert-base-uncased-squad-v1
11
12
13if __name__ == '__main__':
14 parser = argparse.ArgumentParser(description='Preprocess Bert-Squad Model')
15 parser.add_argument(
16 '--input_model', type=str, default='', help='path of input model'
17 )
18 args = parser.parse_args()
19
20 if not os.path.exists(args.input_model):
21 parser.print_usage()
22 raise FileNotFoundError(f'Unable to find model : {args.input_model}')
23
24 model = onnx.load(args.input_model)
25
26 # for packed bert, we need to export position_ids to model's input
27 # step 1: remove unneed node
28 rm_node_names = [
29 'Shape_7',
30 'Gather_9',
31 'Add_11',
32 'Unsqueeze_12',
33 'Slice_14',
34 'Constant_8',
35 'Constant_10',
36 'Constant_13',
37 ]
38 rm_nodes = []
39 for node in model.graph.node:
40 if node.name in rm_node_names:
41 rm_nodes.append(node)
42
43 assert len(rm_node_names) == len(rm_nodes)
44
45 for node in rm_nodes:
46 model.graph.node.remove(node)
47
48 # step 2: add position_ids to model's input
49 position_ids = copy.deepcopy(model.graph.input[0])
50 position_ids.name = 'position_ids'
51 model.graph.input.append(position_ids)
52
53 for node in model.graph.node:
54 if node.op_type == 'Gather' and node.name == 'Gather_18':
55 node.input[1] = position_ids.name
56
57 print(f'Save preprocessed model to bert_base_squad_pos.onnx')
58 onnx.save(model, 'bert_base_squad_pos.onnx')
生成不使用 packing 模型:
python -m poprt.cli \
--input_model squad_bert_base_pos.onnx \
--output_model squad_bert_base_bs16_sl256.onnx \
--precision fp16 \
--input_shape input_ids=16,256 attention_mask=16,256 token_type_ids=16,256 position_ids=16,256
生成 packing 模型:
python -m poprt.cli \
--input_model squad_bert_base_pos.onnx \
--output_model squad_bert_base_bs16_sl256_pack.onnx \
--precision fp16 \
--input_shape input_ids=16,256 attention_mask=16,256 token_type_ids=16,256 position_ids=16,256 \
--pack_args max_valid_num=40 segment_max_size=256
其中, max_valid_num 用于指定 Unpacking 之后的最大 batch size, segment_max_size 表示最大的长度.
运行模型
运行模型的命令如下:
python packed_bert_example.py \
--model_with_packing squad_bert_base_bs16_sl256_pack.onnx \
--model_without_packing squad_bert_base_bs16_sl256.onnx
完整的代码如下:
1# Copyright (c) 2023 Graphcore Ltd. All rights reserved.
2import argparse
3import csv
4import os
5import queue
6import sys
7import tempfile
8import time
9
10from multiprocessing.pool import ThreadPool
11
12import numpy as np
13import packing_utils
14
15from sklearn.metrics import mean_absolute_error
16
17from poprt import runtime
18from poprt.backend import get_session
19
20np.random.seed(2023)
21INPUT_IDS = "input_ids"
22POSITION_IDS = "position_ids"
23ATTENTION_MASK = "attention_mask"
24TOKEN_TYPE_IDS = "token_type_ids"
25UNPACK_INFO = "unpack_info"
26OUTPUT2 = "start_logits"
27OUTPUT1 = "end_logits"
28
29
30class BertInputs(object):
31 def __init__(
32 self,
33 input_ids,
34 attention_mask,
35 token_type_ids,
36 position_ids,
37 unpack_info,
38 input_len,
39 ):
40 self.input_ids = input_ids
41 self.attention_mask = attention_mask
42 self.token_type_ids = token_type_ids
43 self.position_ids = position_ids
44 self.input_len = input_len
45 self.unpack_info = unpack_info
46
47
48def get_synthetic_data(args):
49 input_len = np.random.normal(
50 args.avg_seq_len, args.avg_seq_len, size=args.dataset_size
51 ).astype(np.int32)
52 input_len = np.clip(input_len, 1, args.max_seq_len)
53
54 datasets = []
55 for s_len in input_len:
56 input_ids = np.random.randint(0, args.emb_size, (s_len)).astype(np.int32)
57 attention_mask = np.ones(s_len).astype(np.int32)
58 token_type_ids = np.random.randint(0, 2, (s_len)).astype(np.int32)
59 position_ids = np.arange(s_len).astype(np.int32)
60 unpack_info = np.zeros(args.max_valid_num).astype(np.int32)
61
62 feature = BertInputs(
63 input_ids, attention_mask, token_type_ids, position_ids, unpack_info, s_len
64 )
65 datasets.append(feature)
66
67 return datasets
68
69
70def dump_results(model_name, results):
71 fieldnames = [OUTPUT1, OUTPUT2]
72 filename = os.path.basename(model_name)[:-4] + 'csv'
73 with open(filename, 'w') as f:
74 writer = csv.DictWriter(f, fieldnames=fieldnames)
75 for result in results:
76 dict_name2list = {
77 OUTPUT1: result[OUTPUT1],
78 OUTPUT2: result[OUTPUT2],
79 }
80 writer.writerow(dict_name2list)
81
82
83## create batched inputs and pad samples to max_seq_len
84def padding_data(datasets, index, args):
85 feed_dicts = {}
86 feed_dicts[INPUT_IDS] = np.zeros(
87 (args.batch_size, args.max_seq_len), dtype=np.int32
88 )
89 feed_dicts[ATTENTION_MASK] = np.zeros(
90 (args.batch_size, args.max_seq_len), dtype=np.int32
91 )
92 feed_dicts[POSITION_IDS] = np.zeros(
93 (args.batch_size, args.max_seq_len), dtype=np.int32
94 )
95 feed_dicts[TOKEN_TYPE_IDS] = np.zeros(
96 (args.batch_size, args.max_seq_len), dtype=np.int32
97 )
98
99 for i in range(args.batch_size):
100 input_len = datasets[index].input_len
101 feed_dicts[INPUT_IDS][i][:input_len] = datasets[index].input_ids
102 feed_dicts[ATTENTION_MASK][i][:input_len] = datasets[index].attention_mask
103 feed_dicts[POSITION_IDS][i][:input_len] = datasets[index].position_ids
104 feed_dicts[TOKEN_TYPE_IDS][i][:input_len] = datasets[index].token_type_ids
105 index = index + 1
106 return feed_dicts
107
108
109# online pack, samples feeded to IPU can reach to maximum num of batches in each running turn
110def run_packing_model_with_pack_runner(args, datasets):
111 tmpdir = tempfile.TemporaryDirectory()
112 # export popef for PackRunner
113 get_session(
114 args.model_with_packing, 1, "poprt", output_dir=tmpdir.name, export_popef=True
115 ).load()
116 config = runtime.PackRunnerConfig(
117 timeout_microseconds=args.timeout_microseconds,
118 # max_valid_num=args.max_valid_num,
119 # dynamic_input_name=args.dynamic_input_name,
120 )
121
122 # init PackRunenr
123 popef_path = tmpdir.name + '/executable.popef'
124 # popef_path = "/popconverter/examples/packed_bert_example/executable.popef"
125 pack_runner = runtime.PackRunner(popef_path, config)
126
127 result_queue = queue.Queue()
128 results = []
129 start_time = time.time()
130 for i in range(args.dataset_size):
131 feed_dicts = {
132 INPUT_IDS: datasets[i].input_ids,
133 ATTENTION_MASK: datasets[i].attention_mask,
134 TOKEN_TYPE_IDS: datasets[i].token_type_ids,
135 POSITION_IDS: datasets[i].position_ids,
136 # unpack_info should be hidden from user in the future
137 UNPACK_INFO: np.zeros(args.max_valid_num).astype(np.int32),
138 }
139 out_dict = {
140 OUTPUT1: np.zeros([args.max_seq_len]).astype(np.float16),
141 OUTPUT2: np.zeros([args.max_seq_len]).astype(np.float16),
142 }
143 future = pack_runner.executeAsync(feed_dicts, out_dict)
144 result_queue.put((future, out_dict))
145 result_queue.put((None, None))
146 while True:
147 future, out_dict = result_queue.get()
148 if future == None:
149 break
150 future.wait()
151 results.append(out_dict)
152 end_time = time.time()
153
154 tput = args.dataset_size / (end_time - start_time)
155 latency_ms = (end_time - start_time) / args.dataset_size
156 print(
157 f"[Pack Online] Throughput: {tput} samples/s, Latency : {latency_ms * 1000} ms"
158 )
159
160 if args.dump_results:
161 dump_results("online_" + args.model_with_packing, results)
162
163 tmpdir.cleanup()
164 return results
165
166
167# offline pack, samples feeded to IPU can reach to maximum num of batches in each running turn
168def run_packing_model_with_model_runner(args, datasets):
169 run_queue = queue.Queue()
170 start_time = time.time()
171 index = 0
172 for i in range(0, args.dataset_size):
173 transfer = packing_utils.pack_data(
174 datasets,
175 index,
176 args.batch_size,
177 seq_len=256,
178 max_valid_num=args.max_valid_num,
179 segment_num=1,
180 )
181 run_queue.put(transfer)
182 index = transfer.count
183 if index == args.dataset_size:
184 break
185 run_queue.put(None)
186 duration_of_packing = time.time() - start_time
187 mean_latency_of_padding_us = duration_of_packing * 1e6 / args.dataset_size
188
189 print(f"Mean latency of packing data: {mean_latency_of_padding_us} us/sam")
190 print(f"Total latency of packing data: {duration_of_packing} s")
191
192 sess = get_session(args.model_with_packing, 1, "poprt").load()
193
194 pool = ThreadPool(processes=4)
195
196 def execute(feed_dicts, valid_num):
197 outputs = sess.run([OUTPUT1, OUTPUT2], feed_dicts)
198 res = []
199 for i in range(valid_num):
200 res1 = outputs[0][i].copy().tolist()
201 res2 = outputs[1][i].copy().tolist()
202 res.append({OUTPUT1: res1, OUTPUT2: res2})
203 return res
204
205 asy_results = []
206
207 total_start_time = time.time()
208 while True:
209 input_data = run_queue.get()
210 if input_data is None:
211 break
212
213 feed_dicts = {
214 INPUT_IDS: input_data.data[INPUT_IDS],
215 ATTENTION_MASK: input_data.data[ATTENTION_MASK],
216 TOKEN_TYPE_IDS: input_data.data[TOKEN_TYPE_IDS],
217 POSITION_IDS: input_data.data[POSITION_IDS],
218 # unpack_info should be hidden from user in the future
219 UNPACK_INFO: input_data.unpack_info,
220 }
221 valid_num = len(input_data.specs)
222 async_result = pool.apply_async(execute, (feed_dicts, valid_num))
223 asy_results.append(async_result)
224
225 results = []
226 for asy in asy_results:
227 for res in asy.get():
228 results.append(res)
229 total_end_time = time.time()
230
231 tput = len(results) / (total_end_time - total_start_time)
232 latency = (total_end_time - total_start_time) / len(results)
233
234 print(f"[Pack Offline] Throughput: {tput} samples/s, Latency: {latency*1000} ms")
235
236 if args.dump_results:
237 dump_results("offline_" + args.model_without_packing, results)
238
239 return results
240
241
242# no pack, padding each line with 0 if input length is not long enough.
243# samples num equals to batch at every running turn
244def run_original_model_with_model_runner(args, datasets):
245 run_queue = queue.Queue()
246 start_time = time.time()
247 for i in range(0, args.dataset_size, args.batch_size):
248 feed_dicts = padding_data(datasets, i, args)
249 run_queue.put((args.batch_size, feed_dicts))
250 run_queue.put((0, None))
251 duration_of_padding_s = time.time() - start_time
252
253 mean_latency_of_padding_us = duration_of_padding_s * 1e6 / args.dataset_size
254 print(f"Mean latency of padding data: {mean_latency_of_padding_us} us/sam")
255 print(f"Total latency of padding data: {duration_of_padding_s} s")
256
257 sess = get_session(args.model_without_packing, 1, "poprt").load()
258
259 asy_results = []
260
261 def execute(feed_dicts, valid_num):
262 outputs = sess.run([OUTPUT1, OUTPUT2], feed_dicts)
263 res = []
264 for i in range(valid_num):
265 res1 = outputs[0][i].copy().tolist()
266 res2 = outputs[1][i].copy().tolist()
267 res.append({OUTPUT1: res1, OUTPUT2: res2})
268 return res
269
270 # execute
271 pool = ThreadPool(processes=4)
272 total_start_time = time.time()
273 while True:
274 valid_num, feed_dicts = run_queue.get()
275 if feed_dicts is None:
276 break
277 async_result = pool.apply_async(execute, (feed_dicts, valid_num))
278 asy_results.append(async_result)
279 results = []
280 for asy in asy_results:
281 for res in asy.get():
282 results.append(res)
283 total_end_time = time.time()
284
285 tput = len(results) / (total_end_time - total_start_time)
286 latency = (total_end_time - total_start_time) / len(results)
287
288 if args.dump_results:
289 dump_results("original_" + args.model_without_packing, results)
290
291 print(f"[Original] Throughput: {tput} samples/s, Latency: {latency *1000} ms")
292
293 return results
294
295
296def calculate_mae(expected_results, output_results, datasets, enable_debug):
297 assert len(datasets) == len(expected_results)
298 assert len(datasets) == len(output_results)
299 maes = []
300 zipped_data = zip(datasets, expected_results, output_results)
301 for i, (data, expected, output) in enumerate(zipped_data):
302 np.testing.assert_equal(len(expected), len(output))
303 input_len = data.input_len
304 output_1_mae = mean_absolute_error(
305 expected[OUTPUT1][:input_len], output[OUTPUT1][:input_len]
306 )
307 output_2_mae = mean_absolute_error(
308 expected[OUTPUT2][:input_len], output[OUTPUT2][:input_len]
309 )
310 maes.append([i, output_1_mae, output_2_mae])
311
312 k = 10 if len(datasets) > 10 else len(datasets)
313
314 def print_topk(k, out_name, out_index):
315 for i in range(1, k + 1):
316 print(f"Sample: {maes[-i][0]}, {out_name} mae : {maes[-i][out_index]}")
317
318 if enable_debug:
319 maes.sort(key=lambda e: e[1])
320 print(f"\n***** Top {k} mae of output: {OUTPUT1} *****")
321 print_topk(k, OUTPUT1, 1)
322
323 maes.sort(key=lambda e: e[2])
324 print(f"\n***** Top {k} mae of output: {OUTPUT2} *****")
325 print_topk(k, OUTPUT2, 2)
326
327 print(f"{OUTPUT1} average mae: {np.mean(maes,axis=0)[1]}")
328 print(f"{OUTPUT2} average mae: {np.mean(maes,axis=0)[2]}")
329
330
331def main():
332 parser = argparse.ArgumentParser(description='packed bert-base-squad')
333 parser.add_argument(
334 '--avg_seq_len', type=int, default=128, help='average sequence length of input'
335 )
336 parser.add_argument(
337 '--batch_size', type=int, default=16, help='batch size of model'
338 )
339 parser.add_argument('--dump_results', action='store_true', help='dump results')
340 parser.add_argument(
341 '--dynamic_input_name', type=str, default=INPUT_IDS, help='dynamic input name'
342 )
343 parser.add_argument(
344 '--emb_size', type=int, default=30522, help='word embedding table size'
345 )
346 parser.add_argument(
347 '--enable_debug', action='store_true', help='enable output debug info'
348 )
349 parser.add_argument(
350 '--iterations', type=int, default=100, help='number of batches to run'
351 )
352 parser.add_argument(
353 '--max_seq_len', type=int, default=256, help='max sequence length of input'
354 )
355 parser.add_argument(
356 '--max_valid_num', type=int, default=40, help='max valid num for pack'
357 )
358 parser.add_argument(
359 '--model_without_packing', help='model without pack, unpack, repack op'
360 )
361 parser.add_argument(
362 '--model_with_packing',
363 help='model with pack, unpack, repack op converted by PopRT',
364 )
365 parser.add_argument(
366 '--timeout_microseconds',
367 type=int,
368 default=15000,
369 help='timeout in microseconds',
370 )
371
372 args = parser.parse_args()
373 args.dataset_size = args.iterations * args.batch_size
374
375 # generate synthetic dataset
376 datasets = get_synthetic_data(args)
377 original_result = run_original_model_with_model_runner(args, datasets)
378 offline_pack_result = run_packing_model_with_model_runner(args, datasets)
379 online_pack_result = run_packing_model_with_pack_runner(args, datasets)
380
381 # compare the results
382 print("\nCompare results between original and online pack")
383 calculate_mae(original_result, online_pack_result, datasets, args.enable_debug)
384
385 print("\nCompare results between offline and online pack")
386 calculate_mae(offline_pack_result, online_pack_result, datasets, args.enable_debug)
387
388
389if __name__ == "__main__":
390 sys.exit(main())
运行完成后, 将输出类似如下信息:
[Original] Throughput: 1860.9792005501781 samples/s, Latency: 0.5373515188694 ms
....
[Pack Offline] Throughput: 2830.8140869025283 samples/s, Latency: 0.3532552719116211 ms
....
[Pack Online] Throughput: 2782.587696947809 samples/s, Latency : 0.3593777120113373 ms
....